정렬 알고리즘 (Sorting Algorithm)
date
Apr 18, 2024
slug
sorting
status
Published
tags
Algorithm
summary
type
Post
Bubble Sort (버블 정렬)
앞의 데이터가 뒤의 원소보다 클 경우 자리를 서로 바꾸는 방법이다. 이렇게
N^2번 이중 반복문을 사용하면 정렬이 된다.
그러나 1번 순회를 할 때마다 맨 마지막에는 가장 큰 값이 위치하기 때문에 건들지 않아도 된다.
→ 첫 번째 for문은 i가 N만큼, 두 번째 for문은 j가 N-1-i 만큼 동작하면 된다. 구현하기는 쉽지만 삽입 정렬보다 느리다고 한다.
Insertion Sort (삽입 정렬)
특정 데이터를 적절한 위치에 삽입하는 방법이다.
0번째가 아닌 1번째부터 시작하여 왼쪽 값과 비교하여 자기보다 작은 값이 나올 때까지 이동한다.
선택 정렬은 현재 데이터의 상태와 상관없이 무조건 모든 원소를 비교하고 위치를 바꾸는 반면 삽입 정렬은 그렇지 않다.
→ 삽입 정렬은 필요할 때만 위치를 바꾸기 때문에 선택 정렬에 비해 실행 시간 측면에서 더 효율적인 알고리즘이라고 한다.
Selection Sort (선택 정렬)
가장 작은 데이터를 선택하여 맨 앞에 있는 데이터와 바꾸고, 그 다음으로 작은 데이터를 선택하여 앞에서 두 번째 데이터와 바꾸는 과정을 바꾸는 방법이다.
연산 횟수는 처음에는
N번 만큼 돌면서 가장 작은 값을 찾아야 하고, 두 번째는 N - 1번 돌면서 두 번째로 작은 값을 찾는 과정을 반복한다. 세 번째는 N - 2번, 네 번째는 N - 3번, …
→ N + (N - 1) + (N - 2) + … + 2 → (N^2 + n) / 2 → O(N^2)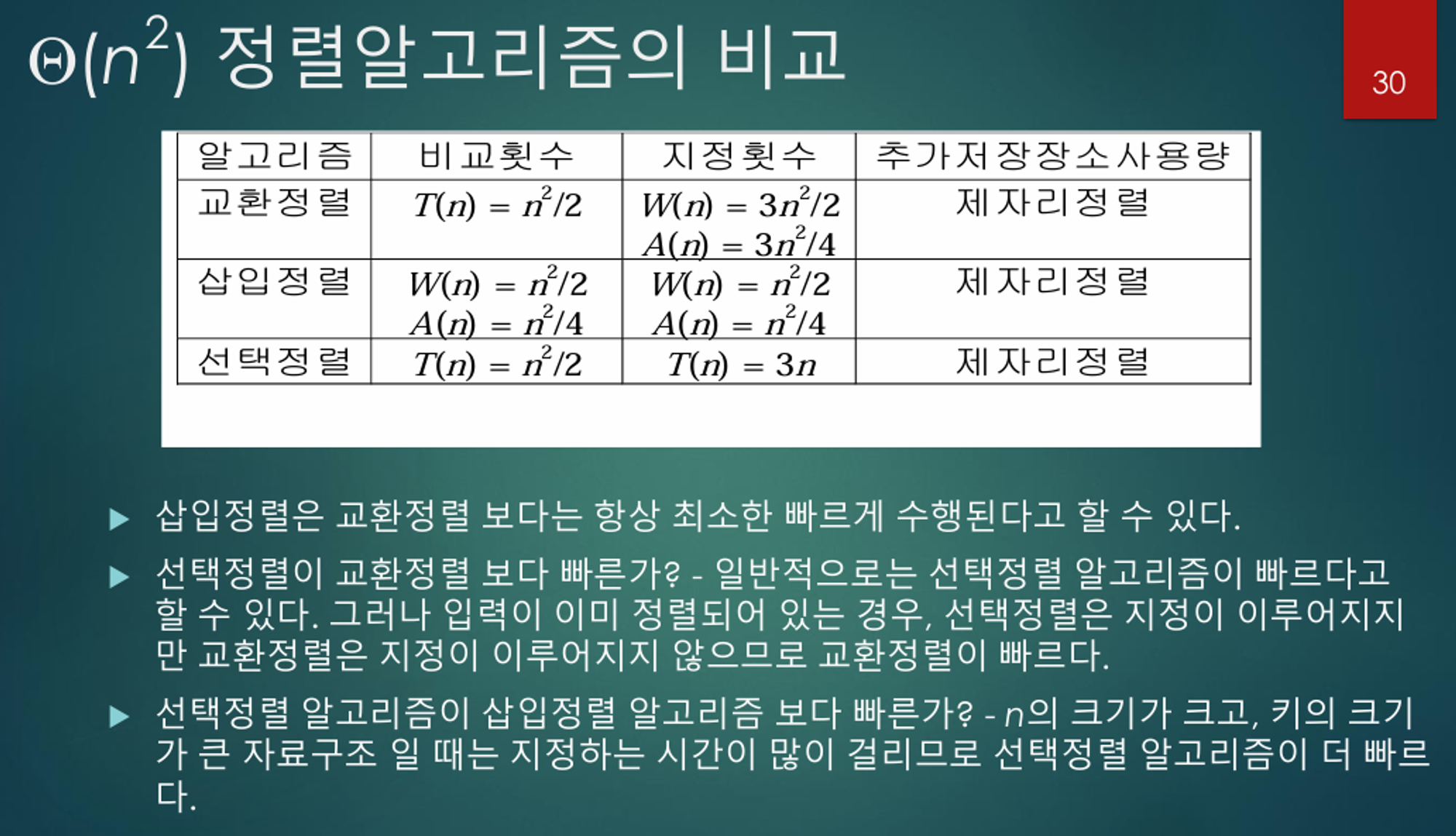
이때
T(n)은 n에 따라 변하게 되는 시간 복잡도(수행 시간), 모든 경우(every-case)의 시간 복잡도라고 볼 수 있다.
W(n)은 최악의 경우에 해당하는 시간 복잡도, B(n)은 최적의 경우에 해당하는 시간 복잡도, A(n)은 평균 복잡도를 의미한다.
최악 시간복잡도를 구하고 싶을 때 T(n)이 존재한다면 T(n) = W(n) 이다.
T(n)이 존재하지 않는 경우, 구할 수 없는 경우에 W(n)을 구하면 된다. A(n) 도 T(n)이 존재하면 T(n) = A(n)이다. B(n)도 마찬가지이다.Quick Sort (퀵 정렬)
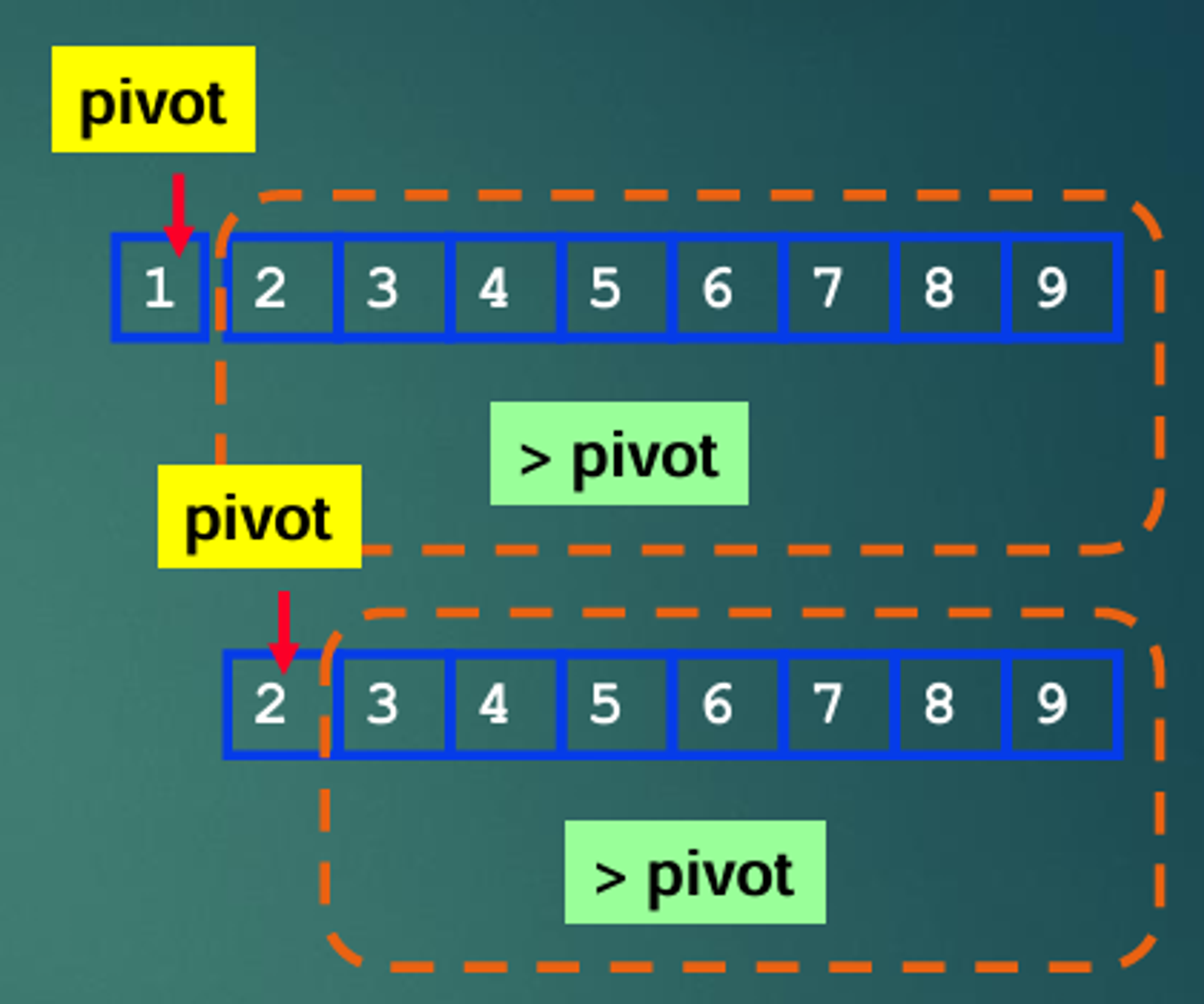
기준점인 pivot을 정하고, pivot 보다 왼쪽에는 작은 데이터들을, 오른쪽에는 큰 데이터들로 위치한 후 정렬을 수행하는 알고리즘이다.
여러 개의 데이터들을 분할하여 정렬하는 대표적인 분할 정복(Divide and Conquer) 알고리즘이다.
정렬된 데이터에 한해서는
O(N^2) 시간 복잡도를 가지게 되는데, 그 이유는 맨 왼쪽 값을 pivot으로 정한다고 했을 때 지정된 pivot 값보다 작은 값은 없기 때문에, 데이터의 개수(N번)만큼 N번 동작하기 때문이다.그러나 다양한 언어에서 제공하는 라이브러리에는 퀵 정렬를 사용한다고 하는데, 바킹독 영상에 의하면 pivot 값을 랜덤으로 선택하거나 일정 깊이 이상 들어가면
O(nlogn)이 보장되는 힙 정렬을 사용한다고 한다.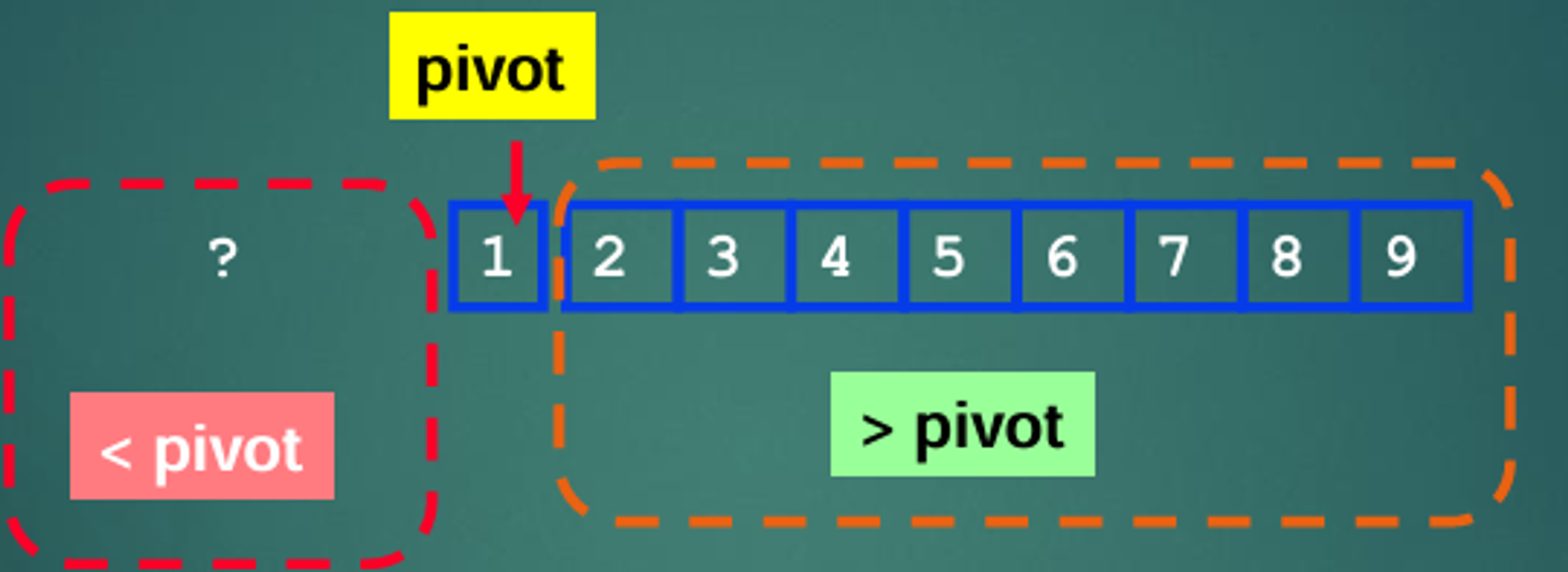
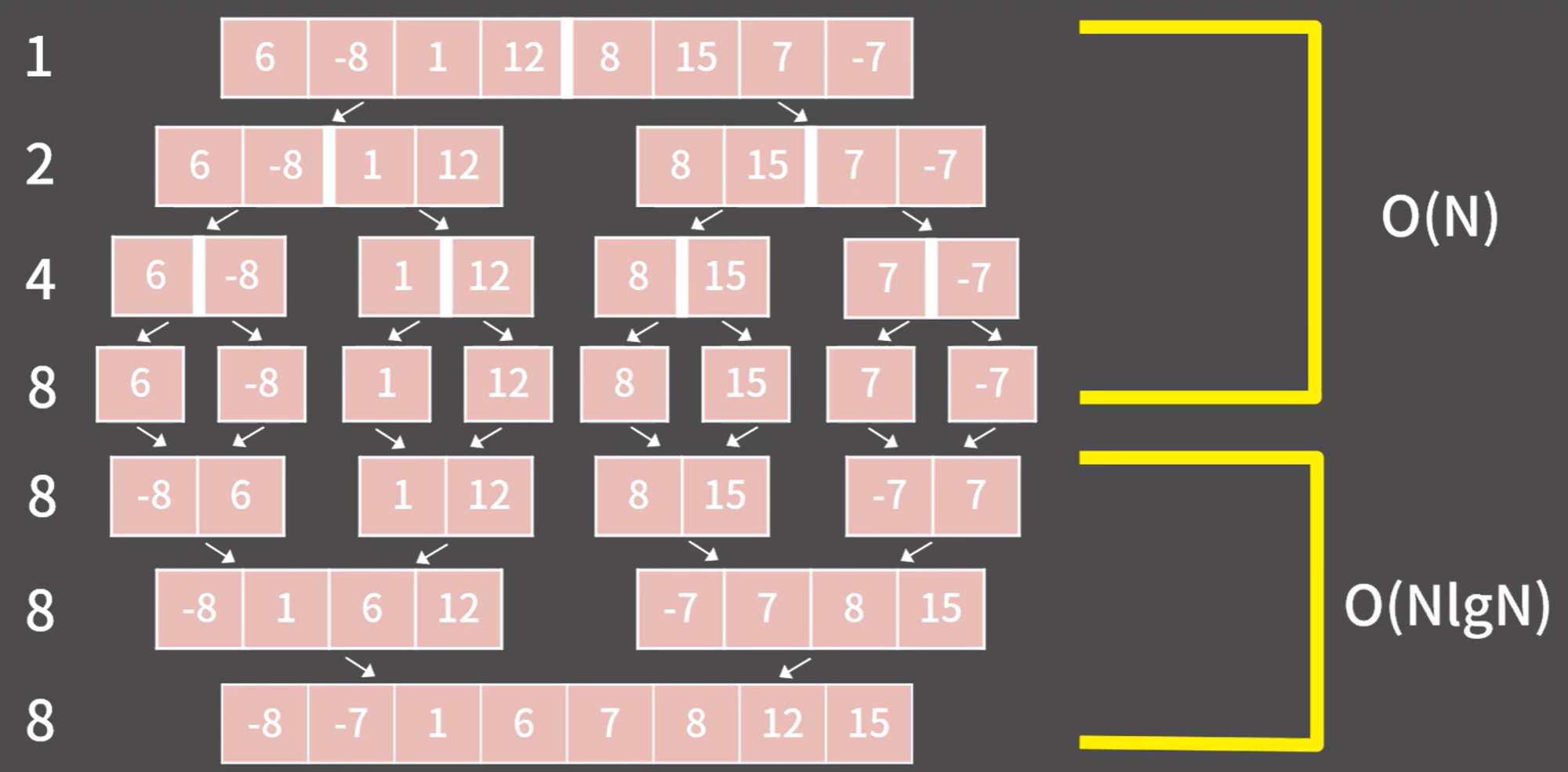
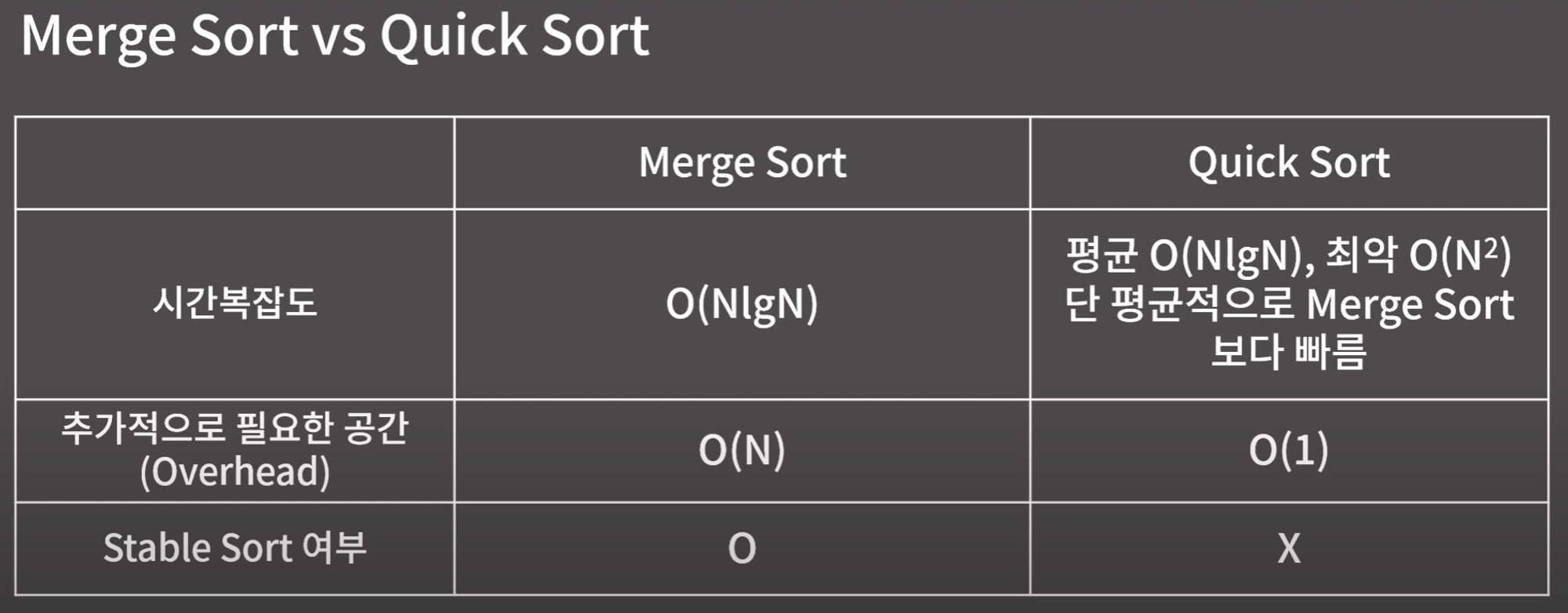
Merge Sort (병합 정렬)
Heap Sort (힙 정렬)
asdasd
Radix Sort (기수 정렬)
asdasd
